
Research Ops at CloudBees
Kicking off Research Operations for Cloudbees enterprise DevOps platform.
Why did I launch ResearchOps?
Isn’t my job UX product design?
Simple, my plan at CloudBees was to create great design, which is a tale of two halves: Building the Right Thing & Building it Right.
The first half was missing - we needed to create it.
-
Build the Right Thing
Kickstart ResearchOps:
- Kickstarted Research Operations practices for scaling Design Discovery;
- Introduced Research Repo & Data Repos.
- Rounded-up and rounded-out the Personas;
- Setup Documentation with guidelines, best practices and mini research roadmaps;
- Improved the tooling for qualitative research handling, tagging, parsing and compiling insights -
Build the Thing Right
UX Design improvements on Core product including:
- Better UX Discovery to our roadmaps,
- Design Systems: Working with Core Design group to build-out and align the Design System(s) for Core product
- Identifying and Fixing UX debt
- Iterative User Testing
- ChatOps: discovery and definition of ChatOps features for Developer Experience
Setting up ResearchOps
Having some experience of a large scale research operation from my Oracle days, I saw that this was missing at CloudBees, and still to be done: I rolled up my sleeves and began installing the following high-level items into our tooling & processes and rolled out in three parts:
Outlined the Double Diamond Design Process;
Created Confluence guidelines & related Jira Epics creating the necessary documentation and task rails for running research operations correctly and efficiently:
Setup ResearchOps Tooling (Shared Research Repo); Socalized it with Design & PM.
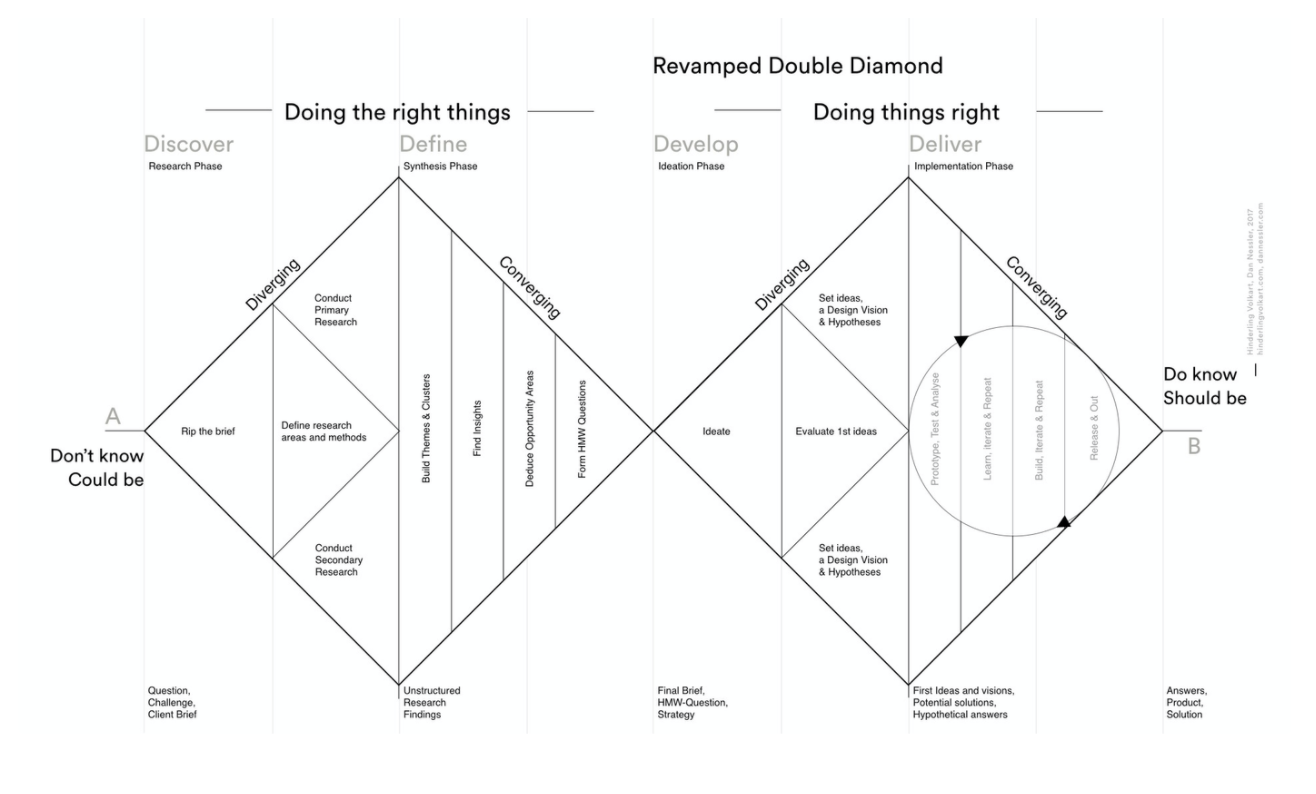
The Double Diamond user experience design Model - my favourite!
Stepping into a new Product Team without much design process calls for some contextual workshops, and an introduction to the designer process. The model I like most and usually use is the Design Council double diamond, which breaks down the Design Thinking process into four sections: Discover, Define, Design/Develop & Deliver. Research ops will cover the first diamond.
The Goal: Map the ResearchOps model over our current toolset.
Because we work in Confuence and Jira it made sense setting up the high-level guidelines and guardrails for running a research operation in those tools primarily.
Here is a diagram and some images of the above flow converted into some Research steps in Confluence:




Next Step: Research Repo
Having a shared research repo is essential to a research-led organisation, informing product across the board and available and open to everyone.
I examined and identified a great tool for this called Dovetail, I made the pitch for it, and we (eventually) bought our licenses, which we then expanded from the design team to the product org.
Before socialising to Design or Product However, we needed some guidelines and guardrails here also.
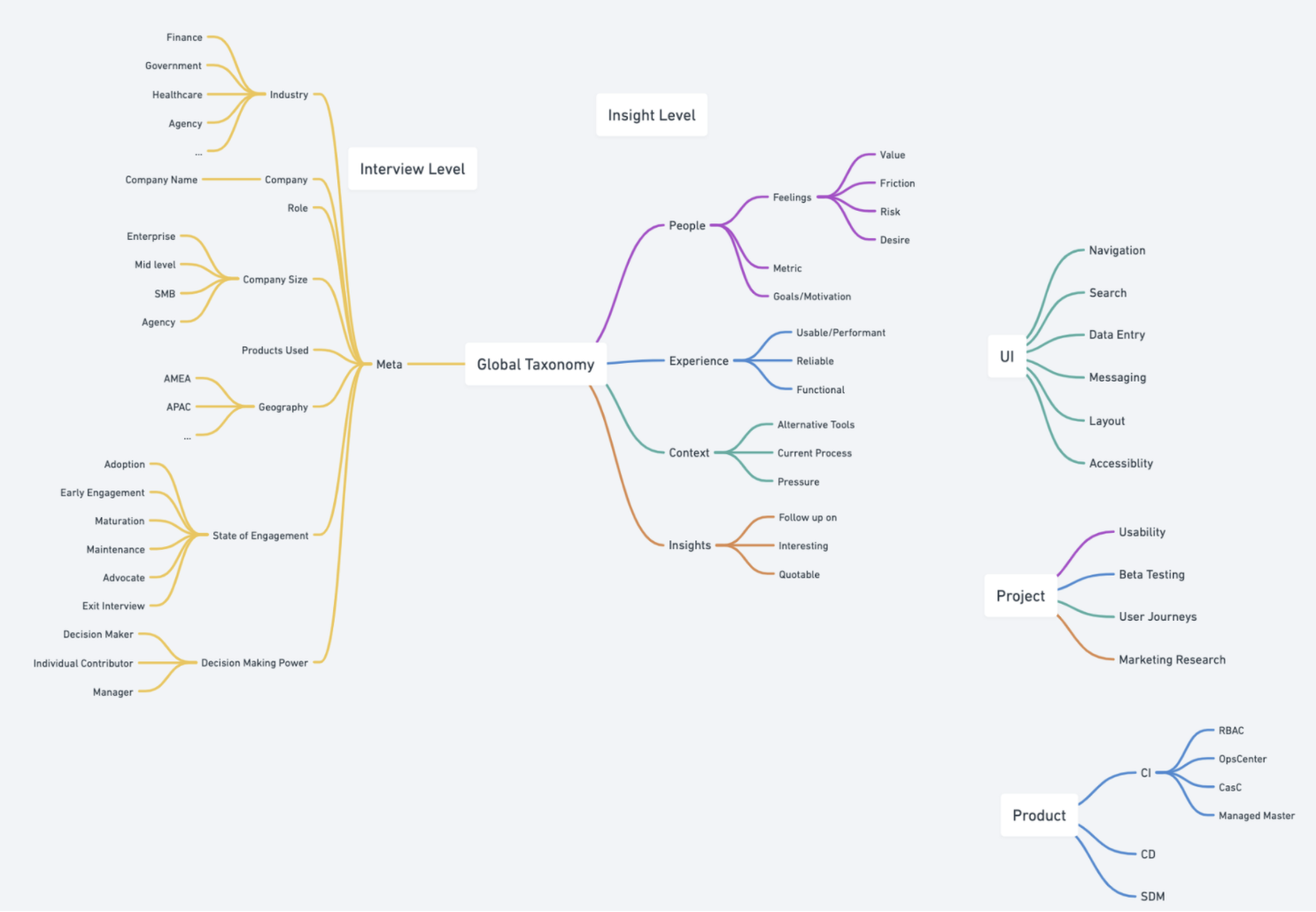
Taxonomy & Tagging
A research repo works by tagging transcripted conversations from interviews: we needed alignment on the tags, so that searching, filtering and categorising is aligned later on.
Here is the preliminary taxonomy we settled on: Meta info for splicing plus People, Experience, Context, Insights & UI.
Using the Taxonomy

Here they are converted into a Global set for all users.

These are then used when tagging transcriptions from user interviews.

And we do a lot user interviews…
Step Three: Parse the data…
The beauty of a tool like Dovetail as a complete research repo and with good data taxonomy is that we can quite quickly pull up insights from searching and filtering across the board on all projects tagged with the same labels:
Splice.

We can search and cross-section our data via our data taxonomy across the board…
Present.
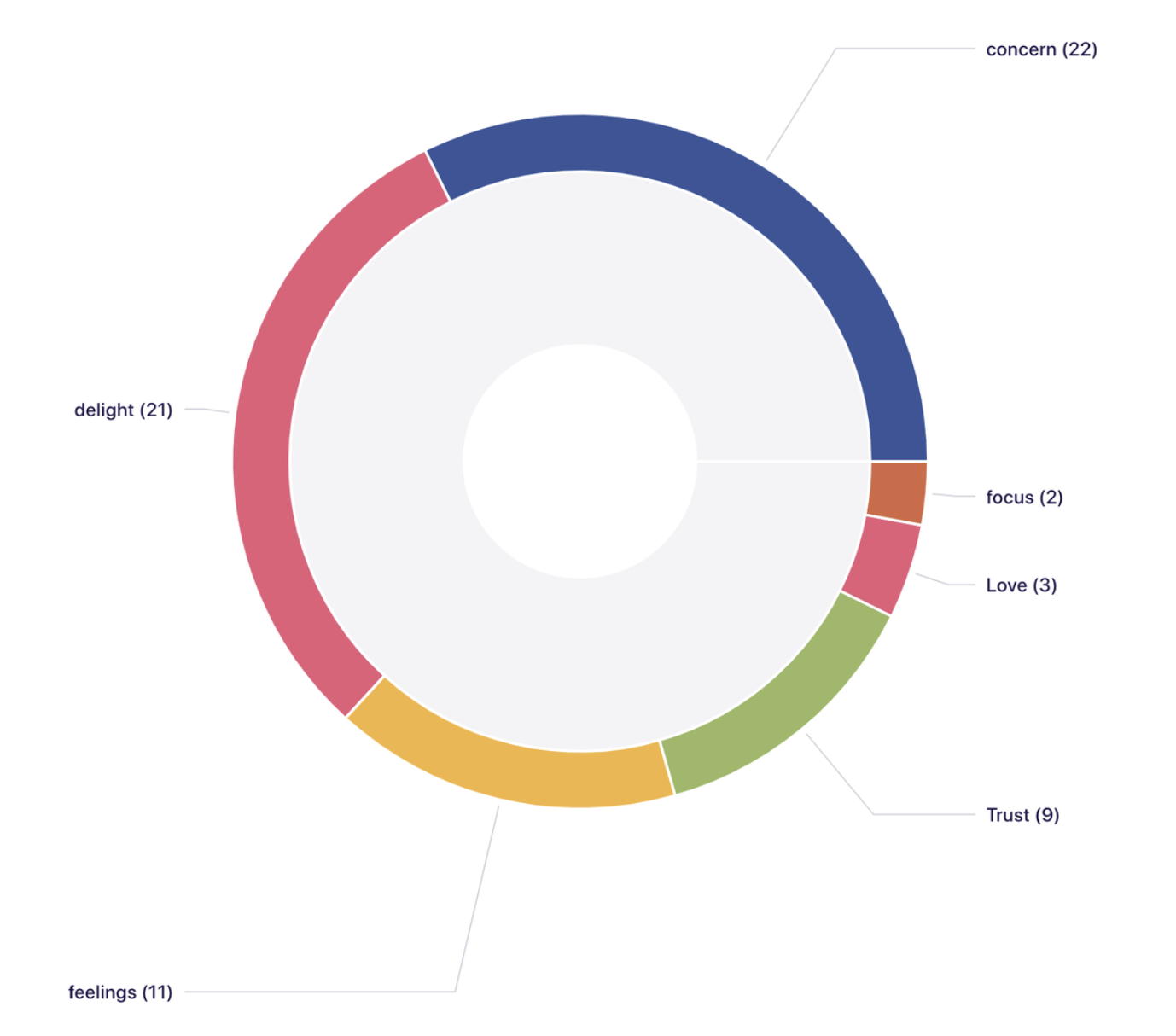
…and gain access to quantitative charts for analysis and presentations…
…and present.
The final piece is to pull together all the insights into Themes which become your insights. Inside each of these are all the comments made by the customers - that you painstakingly tagged and grouped - compiled into nice summaries which are easily fed into the product iteration process.
In this example, some high level insights from the Interviews on DevOps Workload Analytics…

Once this was in place, it’s time to socialise it: The good news is that every Product Owner or Manager who saw this immediately fell in love with it and wanted access. Now, all Design and Product are using this repo. FTW!
From research operations to Product Insights.
The short story of success is that stakeholders were so pleased that they pulled together a Data Insights team which merged into the Design team and we hired our first - and second - researchers!
In addition, research and data is kicking off in a big way at CloudBees, mainly thanks to the open culture and this is a big win for everyone.
Dream it.
The Product Insights team is born…
Build it.
…with plenty to do.